障害管理の課題
仮想インフラストラクチャと物理インフラストラクチャ、内部ネットワークとパブリックネットワーク、複数のアプリケーションで構成されるシステムは、言うまでもなく複雑です。その障害管理においては、常に運用者の課題となっています。従来型の、そして技術的に取り残された企業が行っている、レガシーな障害管理は、ネットワーク、リソース、アプリケーション、のように技術的な要素で分断され、それぞれのレイヤーごとにサイロ化された監視を行っています。そして、サイロ化された各監視システムからは、日々、大量のアラームが通知されます。大量のアラームを受けたサービス信頼性エンジニア(SRE)はそれぞれのアラームを確認、分類し、障害チケットを作成する必要があるかどうかを判断します。
システム間で相互に影響のある問題が生じた場合は、サイロ化された各監視システムからは、同時に複数のチケットが起票され、別々のチームが根本原因の解明に参加し、無駄な調査に時間とリソースを浪費します。データベースの障害が根本原因であるにも関わらず、インフラチーム、ネットワークチーム、アプリケーションチームが全員揃って原因分析をするようなことをしているわけです。
この遅くて労働集約的なレガシー型の監視のアプローチはもはや効果的ではありません。時間と費用がかかりすぎるのはもちろんのこと、お客様のフラストレーションも高まります。
コロナ禍において、突然サービスのスケールアップ、スケールアウトを求められることが、珍しくなくなりました。従来の数倍の処理能力を求められ、システム的にその要求に追従できたとしても、従来型の運用・監視のアプローチを続けているのであれば、それがボトルネックとなります。
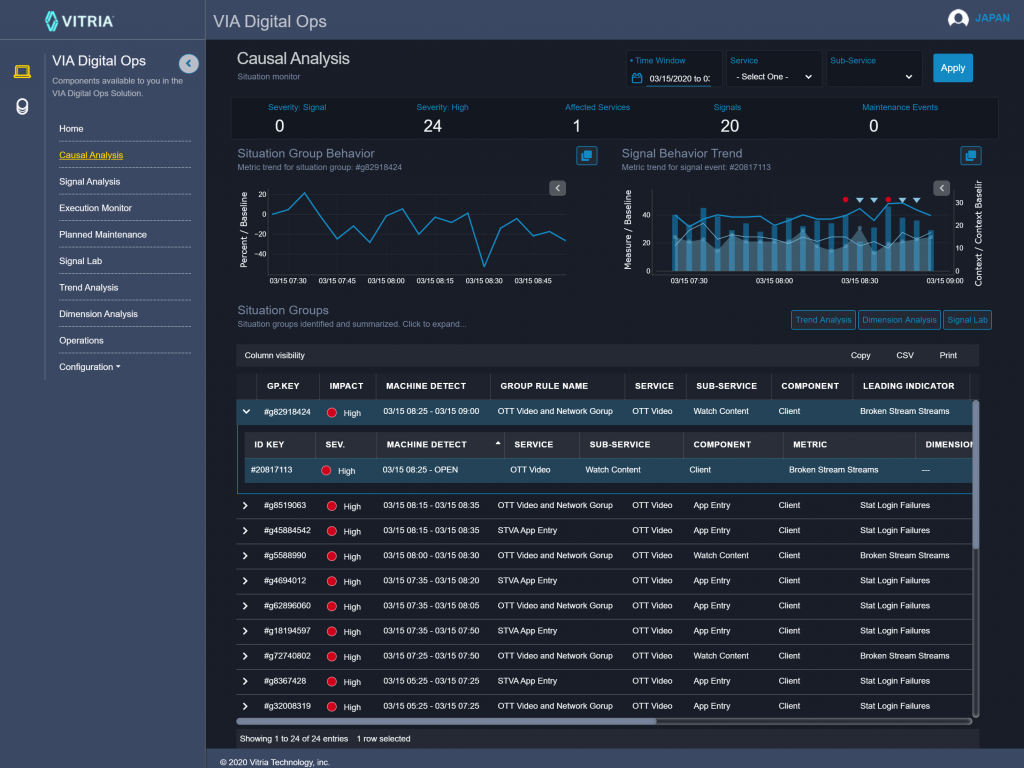
現代のシステム運用において、効果的な障害管理を行うには、「サービスレイヤー全体のアラートノイズの低減」、「人間の介入を減らす自動化」、「既存の監視プロセスと障害管理システムとの統合」が必要です。
サービスの運用を改善するために、AIOpsを導入した組織の成果
AIOpsの導入により、サービスに関わる様々な要素を相関させ分析できるようになりました。
- カスタマーサポートへの問い合わせ件数が、年間で18%減少しました。
- 運用スタッフの補強が 25% 減少しました。
- 監視や運用にかかるツールのライセンスコストが 22% 減少しました。
- エンジニアが訪問して対応しなければならないケースが 12% 減少しました。